Fits an Environmental Vector or Factor onto an Ordination
envfit.RdThe function fits environmental vectors or factors onto an
ordination. The projections of points onto vectors have maximum
correlation with corresponding environmental variables, and the
factors show the averages of factor levels. For continuous variables
this is equal to fitting a linear trend surface (plane in 2D) for a
variable (see ordisurf); this trend surface can be
presented by showing its gradient (direction of steepest increase)
using an arrow. The environmental variables are the dependent
variables that are explained by the ordination scores, and each
dependent variable is analysed separately.
Usage
# Default S3 method
envfit(ord, env, permutations = 999, strata = NULL,
choices=c(1,2), display = "sites", w, na.rm = FALSE, ...)
# S3 method for class 'formula'
envfit(formula, data, ...)
# S3 method for class 'envfit'
plot(x, choices = c(1,2), labels, arrow.mul, at = c(0,0),
axis = FALSE, p.max = NULL, r2.min = NULL, col = "blue", bg,
optimize = FALSE, cex = 1, add = TRUE, ...)
# S3 method for class 'envfit'
scores(x, display = c("vectors", "factors"), choices,
arrow.mul=1, tidy = FALSE, ...)
# S3 method for class 'envfit'
names(x) <- value
vectorfit(X, P, permutations = 0, strata = NULL, w, ...)
factorfit(X, P, permutations = 0, strata = NULL, w, ...)Arguments
- ord
An ordination object or other structure from which the ordination
scorescan be extracted (including a data frame or matrix of scores).- env
Data frame, matrix or vector of environmental variables. The variables can be of mixed type (factors, continuous variables) in data frames.
- X
Matrix or data frame of ordination scores.
- P
Data frame, matrix or vector of environmental variable(s). These must be continuous for
vectorfitand factors or characters forfactorfit.- permutations
a list of control values for the permutations as returned by the function
how, or the number of permutations required, or a permutation matrix where each row gives the permuted indices. Setpermutations = 0to skip permutations.- formula, data
Model
formulaand data.- na.rm
Remove points with missing values in ordination scores or environmental variables. The operation is casewise: the whole row of data is removed if there is a missing value and
na.rm = TRUE.- x
A result object from
envfit. ForordiArrowMulandordiArrowTextXYthis must be a two-column matrix (or matrix-like object) containing the coordinates of arrow heads on the two plot axes, and other methods extract such a structure from theenvfitresults.- choices
Axes to plotted.
- tidy
Return scores that are compatible with ggvegan: all scores are in a single
data.frame, score type is identified by factor variabletype("Vector"or"Centroid"), the names by variablelabel. These scores are incompatible with conventionalplotfunctions, but they can be used in ggvegan and ggplot2.- labels
Change plotting labels. The argument should be a list with elements
vectorsandfactorswhich give the new plotting labels. If either of these elements is omitted orNULL, the default labels will be used. If there is only one type of elements (onlyvectorsor onlyfactors), the labels can be given as vector. The default labels can be displayed withlabelscommand. The argument changes names only in theplotand the fitted object is unchanged; usenamesto change the names in the object.- value
Names of environmental variables used to replace the names in the result object. This should be a list with items
factorsandvectors, or it can be vector of names if only factors or vectors were calculated. If eitherfactorsorvectorsis omitted orNULL, names will not be replaced for that item. The replacement functionnameswill permanently change the result object; use argumentlabelsinplotto change names in the graph and keep the result object unchanged.- arrow.mul
Multiplier for vector lengths. The arrows are automatically scaled similarly as in
plot.ccaif this is not given inplotandadd = TRUE. However, inscoresit can be used to adjust arrow lengths when theplotfunction is not used.- at
The origin of fitted arrows in the plot.
- axis
Add axis of the scaling of fitted arrows in units of correlation on upper and right axes.
- p.max, r2.min
Maximum estimated \(P\) value and minimum \(r^2\) for displayed variables. You must calculate \(P\) values with setting
permutationsto usep.max.- col
Colour in plotting.
- bg
Background colour for labels. If
bgis set, the labels are displayed withordilabelinstead oftext. See Examples for using semitransparent background.- optimize
Optimize the location of text labels to minimize overlap. If
TRUE, factors will be shown with a cross in their exact location, and text for factors and vectors will be optimized.- cex
Character expansion of text labels.
- add
Add results to an existing ordination plot or generate a new plot.
- strata
An integer vector or factor specifying the strata for permutation. If supplied, observations are permuted only within the specified strata.
- display
In fitting functions these are ordinary site scores or linear combination scores (
"lc") in constrained ordination (cca,rda,dbrda). Inscoresfunction they are either"vectors"or"factors"(with synonyms"bp"or"cn", resp.).- w
Weights used in fitting (concerns mainly
ccaanddecoranaresults which have nonconstant weights).- ...
Parameters passed to
scores.
Details
Function envfit finds vectors or factor averages of
environmental variables. Function plot.envfit adds these in
an ordination diagram. If X is a data.frame,
envfit uses factorfit for factor
variables and vectorfit for other variables. If X is
a matrix or a vector, envfit uses only
vectorfit. Alternatively, the model can be defined with a
simplified model formula, where the left hand side
must be an ordination result object or a matrix of ordination
scores, and right hand side lists the environmental variables. The
formula interface can be used for easier selection and/or
transformation of environmental variables. Only the main effects
will be analysed even if interaction terms were defined in the
formula.
The ordination results are extracted with scores and
all extra arguments are passed to the scores. The fitted
models only apply to the results defined when extracting the scores
when using envfit. For instance, scaling in
constrained ordination (see scores.rda,
scores.cca) must be set in the same way in
envfit and in the plot or the ordination results (see
Examples).
The printed output of continuous variables (vectors) gives the
direction cosines which are the coordinates of the heads of unit
length vectors. In plot these are scaled by their
correlation (square root of the column r2) so that
“weak” predictors have shorter arrows than “strong”
predictors. You can see the scaled relative lengths using command
scores. The plotted (and scaled) arrows are further
adjusted to the current graph using a constant multiplier: this will
keep the relative r2-scaled lengths of the arrows but tries
to fill the current plot. You can see the multiplier using
ordiArrowMul(result_of_envfit), and set it with the
argument arrow.mul.
Functions vectorfit and factorfit can be called directly.
Function vectorfit finds directions in the ordination space
towards which the environmental vectors change most rapidly and to
which they have maximal correlations with the ordination
configuration. Function factorfit finds averages of ordination
scores for factor levels. Function factorfit treats ordered
and unordered factors similarly.
If permutations \(> 0\), the significance of fitted vectors
or factors is assessed using permutation of environmental variables.
The goodness of fit statistic is squared correlation coefficient
(\(r^2\)).
For factors this is defined as \(r^2 = 1 - ss_w/ss_t\), where
\(ss_w\) and \(ss_t\) are within-group and total sums of
squares. See permutations for additional details on
permutation tests in Vegan.
User can supply a vector of prior weights w. If the ordination
object has weights, these will be used. In practise this means that
the row totals are used as weights with cca or
decorana results. If you do not like this, but want to
give equal weights to all sites, you should set w = NULL. The
fitted vectors are similar to biplot arrows in constrained ordination
only when fitted to LC scores (display = "lc") and you set
scaling = "species" (see scores.cca). The
weighted fitting gives similar results to biplot arrows and class
centroids in cca.
The lengths of arrows for fitted vectors are automatically adjusted
for the physical size of the plot, and the arrow lengths cannot be
compared across plots. For similar scaling of arrows, you must
explicitly set the arrow.mul argument in the plot
command; see ordiArrowMul.
The results can be accessed with scores.envfit function which
returns either the fitted vectors scaled by correlation coefficient or
the centroids of the fitted environmental variables, or a named list
of both.
Value
Functions vectorfit and factorfit return lists of
classes vectorfit and factorfit which have a
print method. The result object have the following items:
- arrows
Arrow endpoints from
vectorfit. The arrows are scaled to unit length.- centroids
Class centroids from
factorfit.- r
Goodness of fit statistic: Squared correlation coefficient
- permutations
Number of permutations.
- control
A list of control values for the permutations as returned by the function
how.- pvals
Empirical P-values for each variable.
Function envfit returns a list of class envfit with
results of vectorfit and envfit as items.
Function plot.envfit scales the vectors by correlation.
Note
Fitted vectors have become the method of choice in displaying
environmental variables in ordination. Indeed, they are the optimal
way of presenting environmental variables in Constrained
Correspondence Analysis cca and Redundancy analysis
(rda), since there they are the linear constraints.
In unconstrained ordination the relation between external variables
and ordination configuration may be less linear, and therefore other
methods than arrows may be more useful. The simplest is to adjust
the plotting symbol sizes (cex, symbols) by
environmental variables. Fancier methods involve smoothing and
regression methods that abound in R, and ordisurf
provides a wrapper for some.
See also
A better alternative to vectors may be ordisurf.
Examples
data(varespec, varechem)
ord <- metaMDS(varespec)
#> Square root transformation
#> Wisconsin double standardization
#> Run 0 stress 0.1843196
#> Run 1 stress 0.18458
#> ... Procrustes: rmse 0.04934733 max resid 0.157477
#> Run 2 stress 0.1948413
#> Run 3 stress 0.2126568
#> Run 4 stress 0.196245
#> Run 5 stress 0.2067742
#> Run 6 stress 0.2143612
#> Run 7 stress 0.18458
#> ... Procrustes: rmse 0.04935237 max resid 0.1575002
#> Run 8 stress 0.2088293
#> Run 9 stress 0.1825658
#> ... New best solution
#> ... Procrustes: rmse 0.04163799 max resid 0.1518664
#> Run 10 stress 0.1955836
#> Run 11 stress 0.2296578
#> Run 12 stress 0.1852397
#> Run 13 stress 0.2174195
#> Run 14 stress 0.1974406
#> Run 15 stress 0.1967393
#> Run 16 stress 0.18458
#> Run 17 stress 0.2109853
#> Run 18 stress 0.1948413
#> Run 19 stress 0.2251281
#> Run 20 stress 0.1869637
#> *** Best solution was not repeated -- monoMDS stopping criteria:
#> 17: stress ratio > sratmax
#> 3: scale factor of the gradient < sfgrmin
(fit <- envfit(ord, varechem, perm = 999))
#>
#> ***VECTORS
#>
#> NMDS1 NMDS2 r2 Pr(>r)
#> N -0.05725 -0.99836 0.2537 0.052 .
#> P 0.61968 0.78486 0.1938 0.101
#> K 0.76639 0.64238 0.1809 0.114
#> Ca 0.68514 0.72842 0.4119 0.006 **
#> Mg 0.63247 0.77459 0.4270 0.004 **
#> S 0.19132 0.98153 0.1752 0.125
#> Al -0.87164 0.49015 0.5269 0.001 ***
#> Fe -0.93607 0.35180 0.4451 0.001 ***
#> Mn 0.79871 -0.60172 0.5231 0.002 **
#> Zn 0.61754 0.78654 0.1879 0.117
#> Mo -0.90305 0.42953 0.0609 0.537
#> Baresoil 0.92495 -0.38008 0.2508 0.045 *
#> Humdepth 0.93286 -0.36024 0.5200 0.002 **
#> pH -0.64802 0.76162 0.2308 0.068 .
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#> Permutation: free
#> Number of permutations: 999
#>
#>
scores(fit, "vectors")
#> NMDS1 NMDS2
#> N -0.02883469 -0.5028223
#> P 0.27281253 0.3455314
#> K 0.32598275 0.2732335
#> Ca 0.43969547 0.4674715
#> Mg 0.41330987 0.5061844
#> S 0.08008029 0.4108374
#> Al -0.63273148 0.3558013
#> Fe -0.62448384 0.2346992
#> Mn 0.57765369 -0.4351830
#> Zn 0.26769851 0.3409609
#> Mo -0.22293280 0.1060360
#> Baresoil 0.46319165 -0.1903358
#> Humdepth 0.67271731 -0.2597805
#> pH -0.31131128 0.3658875
plot(ord)
plot(fit)
plot(fit, p.max = 0.05, col = "red")
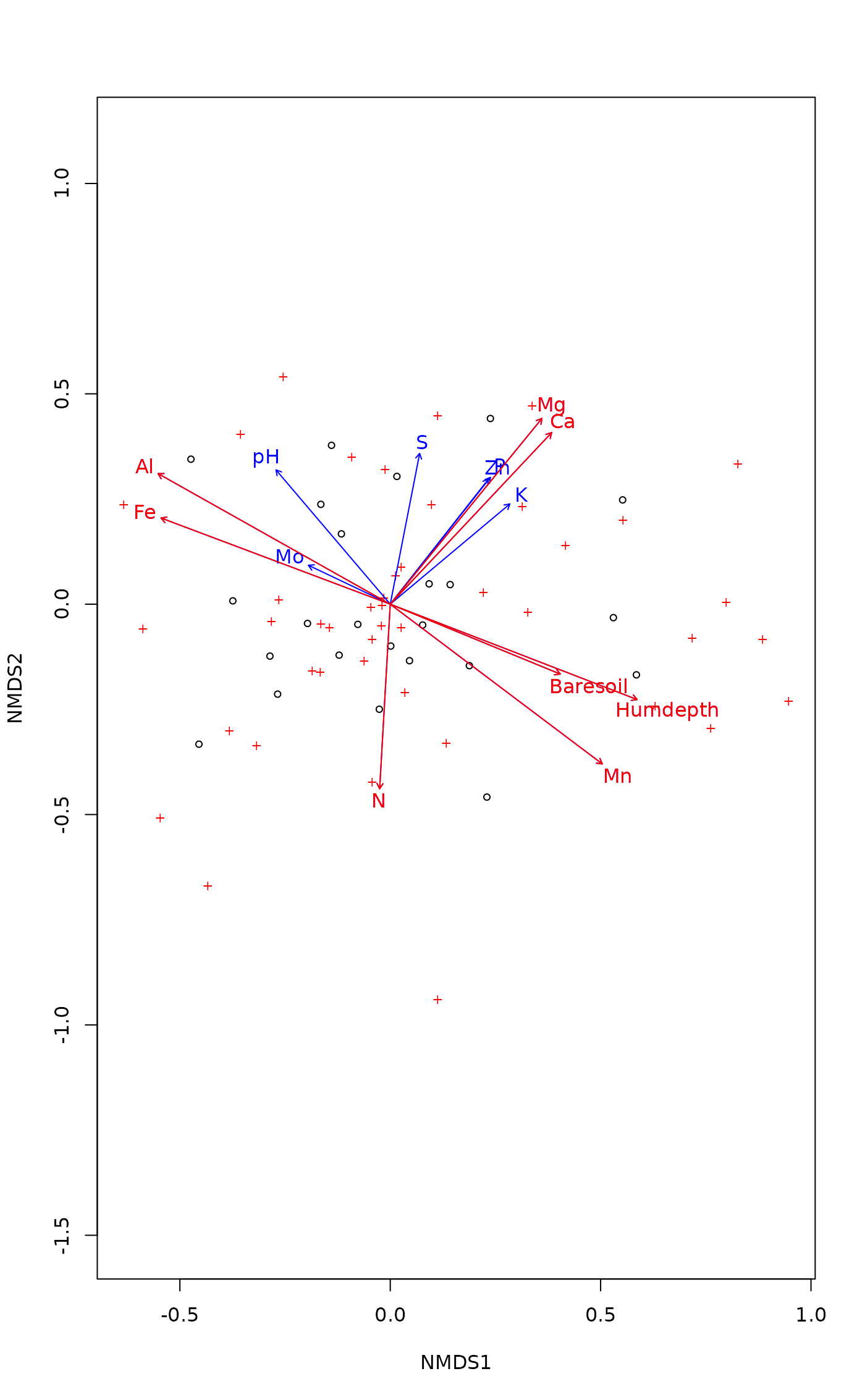 ## Interpretation of fitted arrow: assume linear trend surface, and
## the arrow shows the direction of steepest increase, and fitted
## values are found by projecting points onto the arrow
plot(ord, type = "p")
plot(envfit(ord ~ Al, varechem, permutations = 0))
ordisurf(ord ~ Al, varechem, add = TRUE, knots = 1)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> y ~ poly(x1, 1) + poly(x2, 1)
#> Total model degrees of freedom 3
#>
#> REML score: 125.4218
title(main = "Interpretation of the arrow")
## Interpretation of fitted arrow: assume linear trend surface, and
## the arrow shows the direction of steepest increase, and fitted
## values are found by projecting points onto the arrow
plot(ord, type = "p")
plot(envfit(ord ~ Al, varechem, permutations = 0))
ordisurf(ord ~ Al, varechem, add = TRUE, knots = 1)
#>
#> Family: gaussian
#> Link function: identity
#>
#> Formula:
#> y ~ poly(x1, 1) + poly(x2, 1)
#> Total model degrees of freedom 3
#>
#> REML score: 125.4218
title(main = "Interpretation of the arrow")
 ## Adding fitted arrows to CCA. We use "lc" scores, and hope
## that arrows are scaled similarly in cca and envfit plots
ord <- cca(varespec ~ Al + P + K, varechem)
plot(ord, type="p")
fit <- envfit(ord, varechem, perm = 999, display = "lc")
plot(fit, p.max = 0.05, col = "red")
## Adding fitted arrows to CCA. We use "lc" scores, and hope
## that arrows are scaled similarly in cca and envfit plots
ord <- cca(varespec ~ Al + P + K, varechem)
plot(ord, type="p")
fit <- envfit(ord, varechem, perm = 999, display = "lc")
plot(fit, p.max = 0.05, col = "red")
 ## 'scaling' must be set similarly in envfit and in ordination plot
plot(ord, type = "p", scaling = "sites")
fit <- envfit(ord, varechem, perm = 0, display = "lc", scaling = "sites")
plot(fit, col = "red")
## 'scaling' must be set similarly in envfit and in ordination plot
plot(ord, type = "p", scaling = "sites")
fit <- envfit(ord, varechem, perm = 0, display = "lc", scaling = "sites")
plot(fit, col = "red")
 ## Class variables, formula interface, and displaying the
## inter-class variability with ordispider, and semitransparent
## white background for labels (semitransparent colours are not
## supported by all graphics devices)
data(dune)
data(dune.env)
ord <- cca(dune)
fit <- envfit(ord ~ Moisture + A1, dune.env, perm = 0)
plot(ord, type = "n")
with(dune.env, ordispider(ord, Moisture, col="skyblue"))
with(dune.env, points(ord, display = "sites", col = as.numeric(Moisture),
pch=16))
plot(fit, cex=1.2, axis=TRUE, bg = rgb(1, 1, 1, 0.5))
## Class variables, formula interface, and displaying the
## inter-class variability with ordispider, and semitransparent
## white background for labels (semitransparent colours are not
## supported by all graphics devices)
data(dune)
data(dune.env)
ord <- cca(dune)
fit <- envfit(ord ~ Moisture + A1, dune.env, perm = 0)
plot(ord, type = "n")
with(dune.env, ordispider(ord, Moisture, col="skyblue"))
with(dune.env, points(ord, display = "sites", col = as.numeric(Moisture),
pch=16))
plot(fit, cex=1.2, axis=TRUE, bg = rgb(1, 1, 1, 0.5))
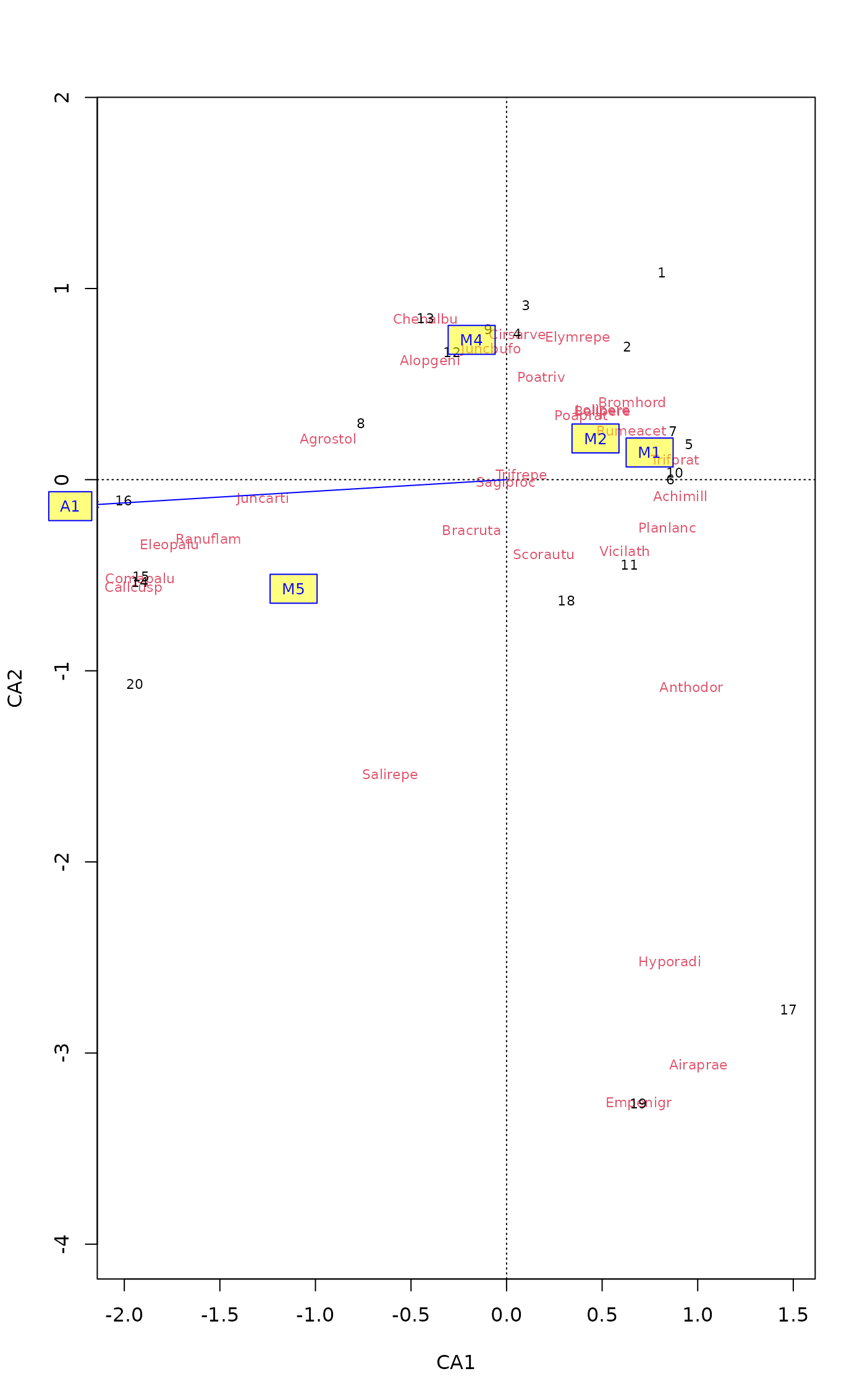 ## Use shorter labels for factor centroids
labels(fit)
#> $vectors
#> [1] "A1"
#>
#> $factors
#> [1] "Moisture1" "Moisture2" "Moisture4" "Moisture5"
#>
plot(ord)
plot(fit, labels=list(factors = paste0("M", c(1,2,4,5))),
bg = rgb(1,1,0,0.5))
## Use shorter labels for factor centroids
labels(fit)
#> $vectors
#> [1] "A1"
#>
#> $factors
#> [1] "Moisture1" "Moisture2" "Moisture4" "Moisture5"
#>
plot(ord)
plot(fit, labels=list(factors = paste0("M", c(1,2,4,5))),
bg = rgb(1,1,0,0.5))
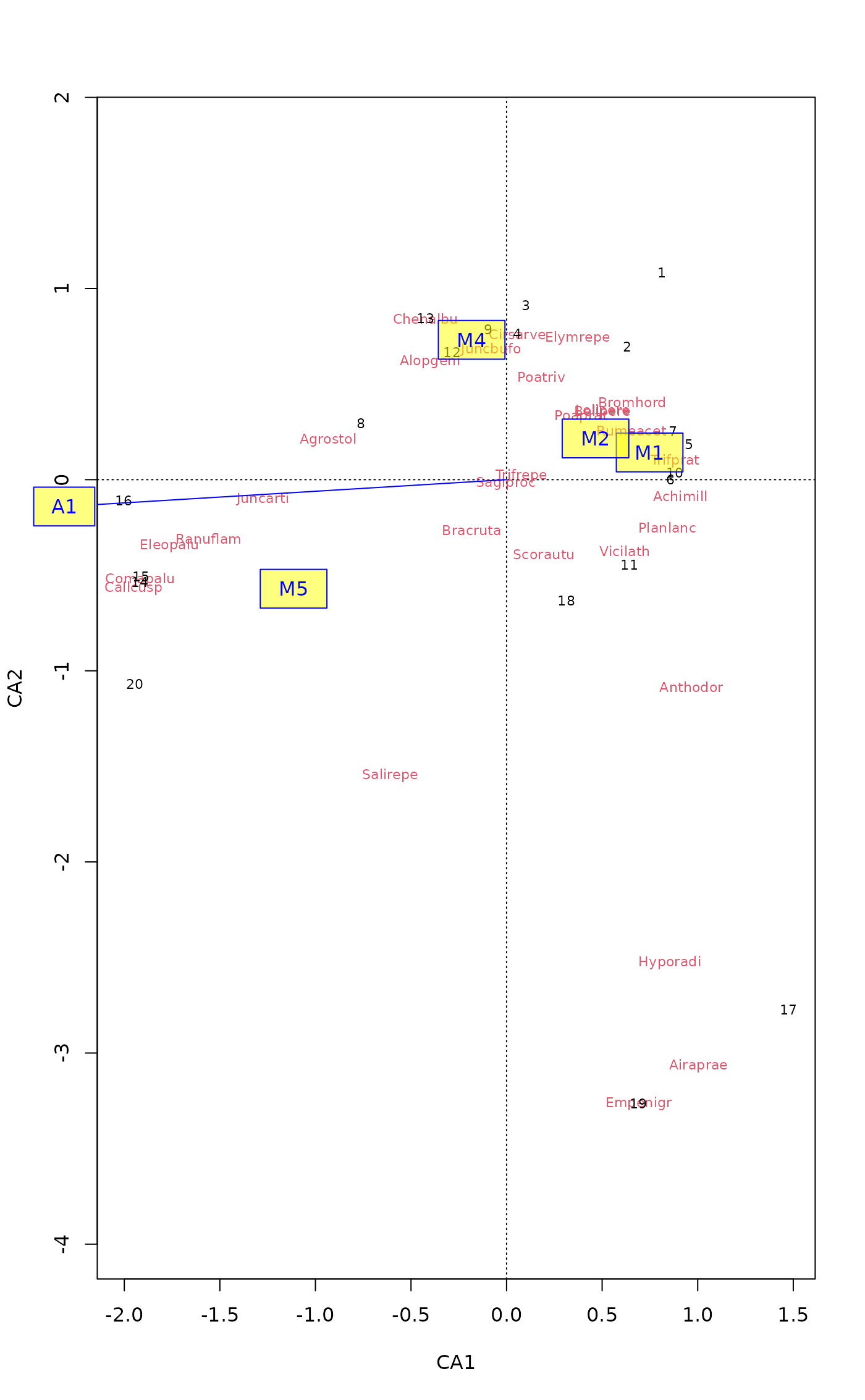 ## change names permanently
names(fit) <- list(factors = paste0("M", c(1,2,4,5)))
fit
#>
#> ***VECTORS
#>
#> CA1 CA2 r2
#> A1 -0.998160 -0.060614 0.3104
#>
#> ***FACTORS:
#>
#> Centroids:
#> CA1 CA2
#> M1 0.7484 0.1423
#> M2 0.4652 0.2156
#> M4 -0.1827 0.7315
#> M5 -1.1143 -0.5708
#>
#> Goodness of fit:
#> r2
#> Moisture 0.4113
#>
#>
## change names permanently
names(fit) <- list(factors = paste0("M", c(1,2,4,5)))
fit
#>
#> ***VECTORS
#>
#> CA1 CA2 r2
#> A1 -0.998160 -0.060614 0.3104
#>
#> ***FACTORS:
#>
#> Centroids:
#> CA1 CA2
#> M1 0.7484 0.1423
#> M2 0.4652 0.2156
#> M4 -0.1827 0.7315
#> M5 -1.1143 -0.5708
#>
#> Goodness of fit:
#> r2
#> Moisture 0.4113
#>
#>